
La grande mode du moment, c’est l’AI générative ou LLM pour Large Language Model. Je suis bien sûr très intéressé par ces applications, tant en termes de génération de texte ou d’image pour des usages pro (résumé, mails, génération de modèles, programmation) et persos (jeu de rôle). Pour cela, on peut utiliser les classiques et plus connus Midjourney ou ChatGPT ou se tourner vers l’open-source et ses bienfaits. Cet article se base principalement sur une vidéo de NetworkChuck que je vous invite à visionner (en anglais), et à diverses informations rassemblées sur le net.
Petit disclaimer : je suis parfaitement conscient de l’impact que ces technologies peuvent avoir sur les métiers de création, illustrateurs, traducteurs, ou autres. Je sais aussi comment sont nourris les modèles de données, la plupart du temps sans considération ni rémunérations pour les auteurs (dont je suis parfois), et c’est un problème grave dont il faut s’occuper dès maintenant. Je n’encourage pas le commerce de produits générés par IA, livres ou images. Je ferai peut-être ultérieurement un article plus complet sur mon positionnement.
Matériel
Contrairement à ce que dit la vidéo de NetworkChuck, pas besoin d’une machine de guerre à base de double RTX 4090 et je ne sais combien de RAM. Vous aurez des résultats parfaitement satisfaisants avec une machine relativement récente. Par contre, une carte graphique Nvidia me semble obligatoire. C’est elle qui fera les calculs, et plus elle sera puissante, plus les retours seront rapides. Le système peut toutefois tourner sur CPU uniquement.
Personnellement j’ai une RTX 4070 12 Go, mais une génération précédente fera parfaitement l’affaire. Idem, n’importe quel processeur un peu récent ira bien.
Par contre, si vous ne disposez que d’un laptop ou un minipc, je ne garantis pas le résultat.
WSL
La plupart des programmes et commandes fonctionnent sur tous les systèmes, mais je trouve que le plus simple c’est Wsl, la version Windows de Linux.
On commence par l’activer en lançant la commande suivante dans le terminal de Windows.
wsl --installCa ne prend que quelques minutes.
Si vous utilisez le Terminal de Windows, vous aurez automatiquement une nouvelle entrée.
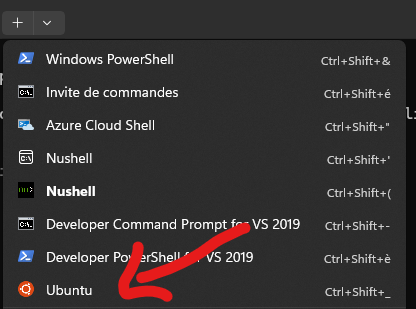
Cliquez dessus pour ouvrir une session Ubuntu.
Il vous demandera un nom d’utilisateur et un mot de passe, puis vous aurez accès à la ligne de commande.
Ubuntu + Docker
Commencez par mettre à jour Ubuntu avec les commandes suivantes :
sudo apt update && sudo apt upgradePuis installez Docker
sudo apt install docker.ioTout est prêt !
Ollama
Ollama est un outil permettant de télécharger et d’utiliser n’importe quel modèle de données disponibles en open-source (et gratuitement) sur le site de Huggin Face, la principale communauté AI. C’est un serveur qui tourne en arrière-plan et qui peut être utilisé en ligne de commande ou via une interface Web qu’on installera juste après.
Pour l’installer, tapez la commande suivante :
curl -fsSL https://ollama.com/install.sh | shAu bout de quelques minutes, vous aurez accès à l’application.
Téléchargez un modèle, je suggère le plus puissant du moment, avec un excellent rapport taille/qualité, Llama3
ollama pull llama3Attention, c’est un fichier de 5Go, la vitesse dépend de la qualité de votre ligne.
Pour tester :
ollama run llama3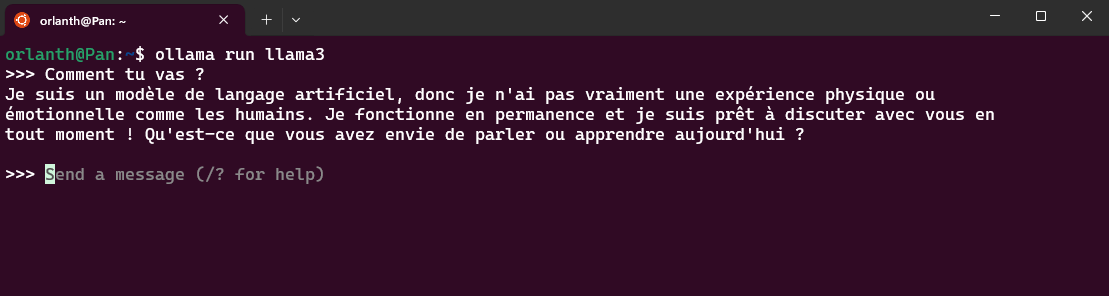
Yeah \o/
OpenWeb UI
C’est un logiciel qui donne une interface graphique à Ollama, ressemblant fortement à celle de ChatGPT ou you.com. On peut télécharger des modèles, discuter avec eux, uploader des fichiers pour les interroger et faire plein de choses cools.
Pour l’installer (toujours dans notre session Ubuntu)
docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:mainLa commande peut faire peur, mais elle dit juste que l’application doit tourner dans docker, que l’image s’appelle open-webui et que le serveur ollama tourne en local. Rien de foufou ou de dangereux.
Comme pour les précédentes commandes, il va télécharger ses fichiers et tout lancer tout seul.
Pour savoir si cela fonctionne, lancer votre navigateur préféré et faites le pointer sur :
http://localhost:8080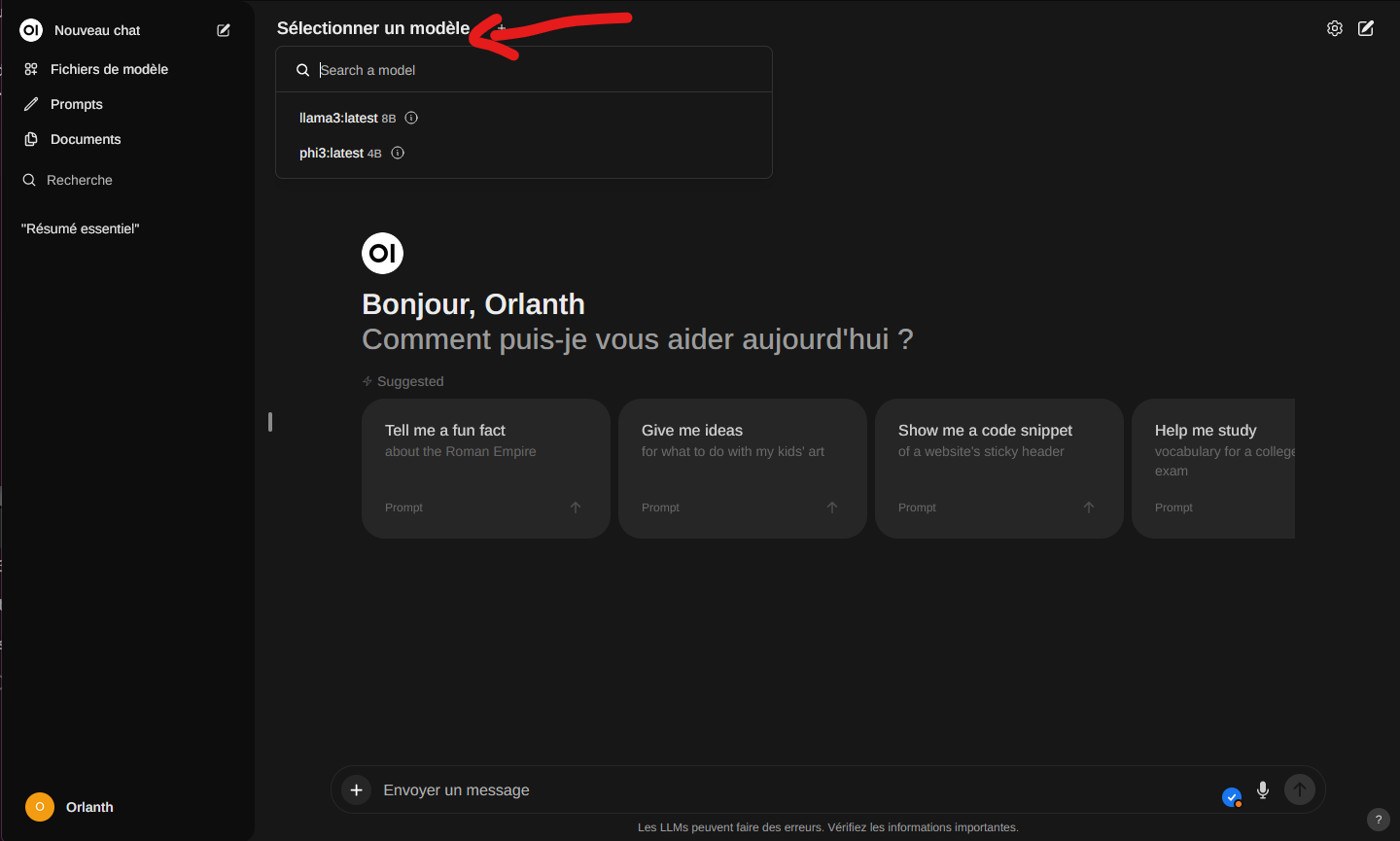
Dans le menu du haut, vous pouvez choisir vote modèle (llama3).
Dans le chat du bas, vous pouvez taper votre question ou demande pour commencer à l’utiliser.
Vous pouvez aussi cliquer sur le petit + en bas à gauche pour envoyer un fichier pour l’interroger. Ça marche avec du texte, mais par la suite, on pourra envoyer une image pour lui faire décrire un prompt qu’on enverra ensuite dans Stable Diffusion.
Le micro permet d’envoyer du son qui sera analysé par Whisper et transformé en texte.
Enfin, les résultats peuvent être lus par une voix synthétique en un clic, je vous montre ça après.
Conclusion de la partie 1
En quelques commandes, on a installé un système complet, accessible facilement, quasiment aussi puissant que le dernier ChatGPT. Si un modèle plus puissant sort en open-source, il sera rendu disponible dans l’application en une commande (ou quelques clics dans l’interface).
Dans la partie 2, nous installerons les autres outils et nous verrons comment les utiliser et les faire échanger entre eux.