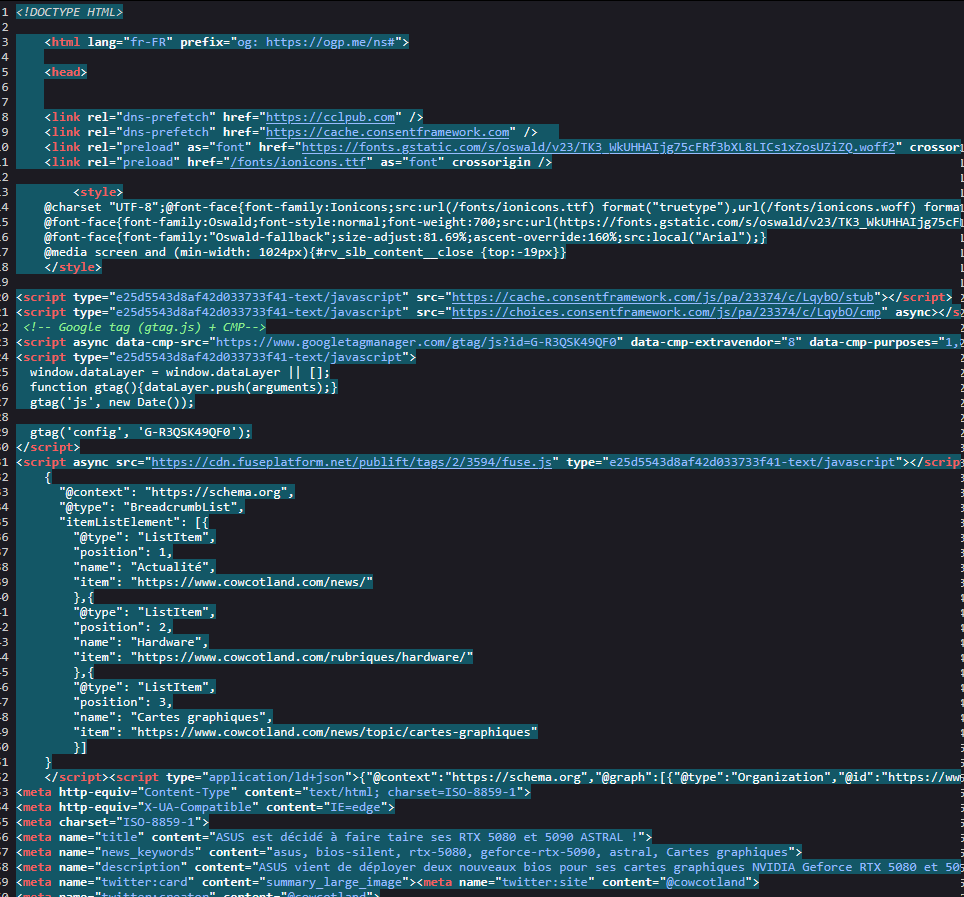
Ca y’est, j’ai terminé la réécriture complète du système de YxY. J’ai appelé ça Aventures parce que j’ai pas d’autres idées et que c’est un système multi univers. Il y a les règles de bases, suffisantes pour la plupart des parties one shots, et des règles avancées si on veut aller plus loin, utiles principalement pour le jeu en campagne, mais pas que.
J’espère ne pas avoir laissé trop de fautes, malgré mes dizaines de relectures, il peut toujours en rester, n’hésitez pas à me les signaler.
J’ai écrit tout le projet sous Obsidian, et produit le document final à l’aide de l’export PDF, notamment les plugins Better PDF et Break Page. C’est encore un document de travail, il n’y a pas de table de matières, ou de pagination, c’est du brut de brut. Je ferai une vraie mise en page s’il y en a besoin, pour l’instant ce n’est pas le cas.
Il n’y a pas d’illustrations parce que je ne suis pas illustrateur, que c’est un document de jeu, et que je ne veux pas utiliser l’IA.