J’utilise depuis des années Freshrss, un lecteur de flux RSS qui possède une option permettant de récupérer le contenu complet d’un flux RSS tronqué. Il existe bien des services externes ou autohebergé comme fulltextrss, mais l’outil le propose en natif. Suite à la perte de mon FreshRss parce que mes sauvegardes ne fonctionnaient pas (tester les restaurations les gens), j’ai réinstallé l’outil et ajouté mes flux un par un. Pour récupérer un flux complet, il faut aller sur la site voulu, utiliser l’inspecteur du navigateur, chercher les selecteurs CSS qui vont bien, faire des copiers-coller, tester et recommencer jusqu’à obtiention du résultat. Voyons comment éviter ces étapes et accélérer la procédure.
Outils
Je suis client Free mobile, et la société vient de nouer un partenariat avec Mistral IA qui offre la version pro pendant un an. Je vais donc m’en servir.
Côté FreshRSS
Ouvrez les paramètres du flux et descendez jusqu’aux selecteurs :

Nous voulons récupérer deux listes de selecteurs, le premier est celui qui contiendra les articles eux-mêmes, le contenu réel. La seconde liste de selecteurs contiendra tout ce qui n’est pas lié à l’article mais qui aurait été inclus dans le premier selecteur. Il peut s’agir d’images, de renvoi vers d’autres articles, de liens sponsorisés, de logo de partage vers les réseaux sociaux, de commentaires ou autres. Tous les selecteurs de cette liste seront supprimé du contenu final.
Astuce : pour tester le résultat, cliquez sur l’icone en forme d’oeil !
Sur le site Web
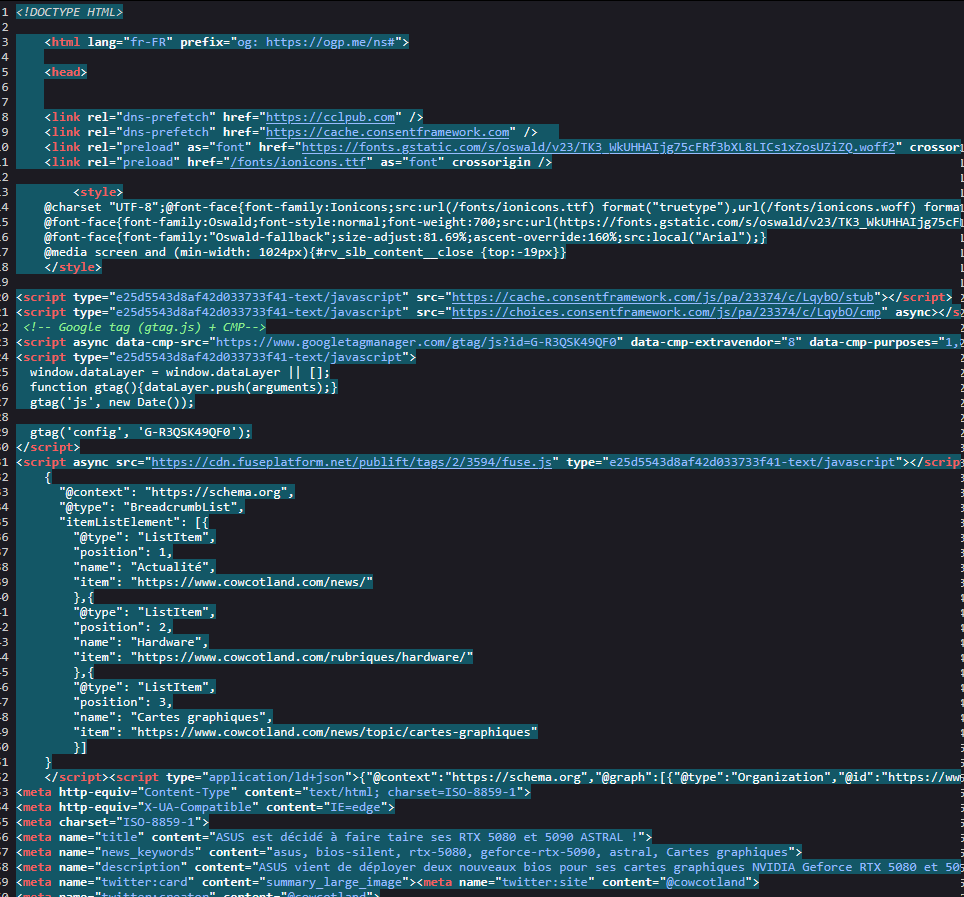
Ouvrez le site web cible, puis appuyez sur ctrl+u pour ouvrir la source.
Ensuite, selectionnez (ctrl+a) puis copiez tout le contenu (ctrl+c).
Dans MISTRAL AI
Ouvrez Mistral AI (ou ChatGPT, ou Perplexity, ou n’importe quel autre outil dans le même genre), puis créer un prompt avec votre demande et collez le texte (ctrl+v).
Ici le prompt est :
Dans la page web suivante, je veux que tu extraits le selecteur permettant de lire uniquement l'article.
Dans cet article, fais la liste de tous les selecteurs qui ne sont pas pertinents dans le texte, par exemple les commentaires, les rappels à lire, les tags, les liens sortants, les réseaux sociaux ou autre.
Rassemble tous les selecteurs trouvés dans une liste séparées par des virgules. 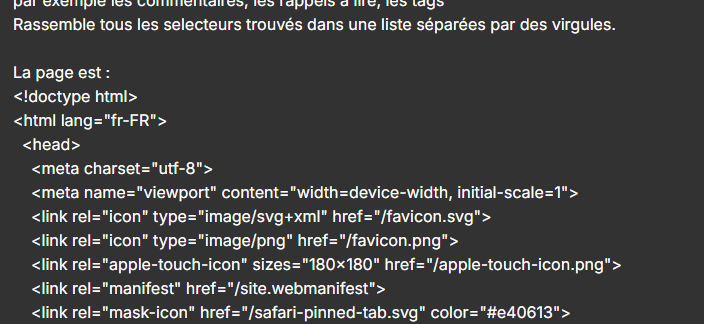
Chez moi le résultat donne ceci :
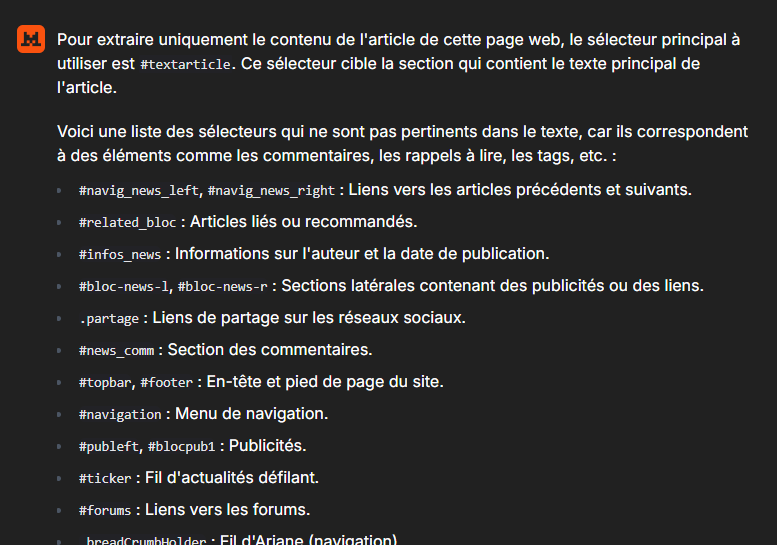
Je saisis #textarticle dans la boite de FreshRss et je teste en cliquant sur l’icone.
Le résultat est parfait, et, dans ce cas précis, je n’ai pas besoin des autres selecteurs. Si cela avait été le cas, j’aurais ajouté à la seconde boite, un par un, séparé par des espaces, chzque sélecteur et en testant à chaque fois pour vérifier que le résultat est ok.
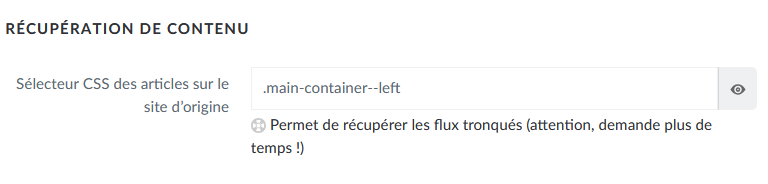
Par exemple, voici le résultat sur Ecran Large :

Conclusion
Chaque site me prend maintenant trois minutes au lieu de 20 minutes et plus en tests, échec, et nouvelles tentatives, tout en cherchant à l’oeil les différents selecteurs.
Est-ce que je pourrais le faire à la main ? Oui, mais c’est plus long, et pénible.
Est-ce que ça vaut le coup de participer à la destruction de la planète en explosant les coûts énergétiques ds entreprises qui proposent ce genre de service ? Sans doute pas en effet.
A vous de voir, mais mon avis est fait et il se trouve ici.